
How to build a rich dataset using web scraping with Python
How to easily create a comprehensive sports statistics database by writing a programming script that can scrape data from multiple web pages with the click of a button
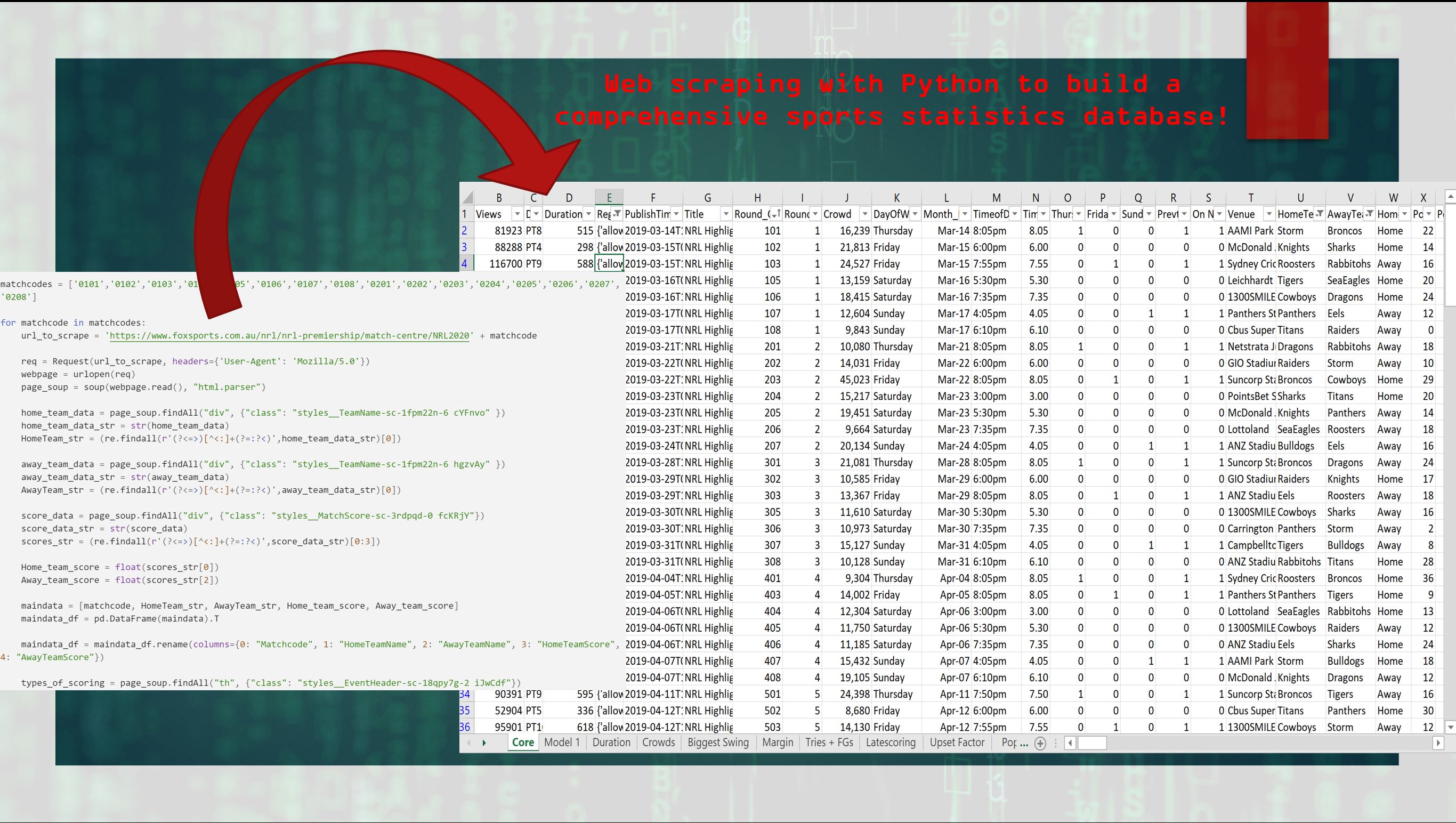
In this video tutorial I demonstrate how to create a sports statistics database using the simple, yet powerful data extraction technique known as web scraping. This technique involves collecting data across multiple web pages without having to open a web browser.
Tutorial:
Code used:
# How to efficiently create a comprehensive sports statistics data set using web scraping and Python
# Install the following python modules
#1 pip install urllib3
#2 pip install bs4
#3 pip install regex
#4 pip install pandas
from urllib.request import Request #1 opening website to scrape
from urllib.request import urlopen #1 opening website to scrape
from bs4 import BeautifulSoup as soup #2 webscraping HTML data
import re #3 to parse html text
import pandas as pd #4 storing data in data frames
# https://www.foxsports.com.au/nrl/nrl-premiership/match-centre/NRL20200101
allmatchcodes_list =[]
matchcodes = ['0101','0102','0103','0104','0105','0106','0107','0108','0201','0202','0203','0204','0205','0206','0207','0208']
for matchcode in matchcodes:
url_to_scrape = 'https://www.foxsports.com.au/nrl/nrl-premiership/match-centre/NRL2020' + matchcode
req = Request(url_to_scrape, headers={'User-Agent': 'Mozilla/5.0'})
webpage = urlopen(req)
page_soup = soup(webpage.read(), "html.parser")
home_team_data = page_soup.findAll("div", {"class": "styles__TeamName-sc-1fpm22n-6 cYFnvo" })
home_team_data_str = str(home_team_data)
HomeTeam_str = (re.findall(r'(?<=>)[^<:]+(?=:?<)',home_team_data_str)[0])
away_team_data = page_soup.findAll("div", {"class": "styles__TeamName-sc-1fpm22n-6 hgzvAy" })
away_team_data_str = str(away_team_data)
AwayTeam_str = (re.findall(r'(?<=>)[^<:]+(?=:?<)',away_team_data_str)[0])
score_data = page_soup.findAll("div", {"class": "styles__MatchScore-sc-3rdpqd-0 fcKRjY"})
score_data_str = str(score_data)
scores_str = (re.findall(r'(?<=>)[^<:]+(?=:?<)',score_data_str)[0:3])
Home_team_score = float(scores_str[0])
Away_team_score = float(scores_str[2])
maindata = [matchcode, HomeTeam_str, AwayTeam_str, Home_team_score, Away_team_score]
maindata_df = pd.DataFrame(maindata).T
maindata_df = maindata_df.rename(columns={0: "Matchcode", 1: "HomeTeamName", 2: "AwayTeamName", 3: "HomeTeamScore", 4: "AwayTeamScore"})
types_of_scoring = page_soup.findAll("th", {"class": "styles__EventHeader-sc-18qpy7g-2 iJwCdf"})
typesofpts_featured_list = []
for i in types_of_scoring:
string_a = str(i)
string_b = string_a.replace(" ", "")
extracter_a = (re.findall(r'(?<=>)[^<:]+(?=:?<)',string_b)[0:10])
typesofpts_featured_list.append(extracter_a)
typesofpts_featured_list_new = []
for i in typesofpts_featured_list:
string_aa = str(i).strip("[]")
string_bb = str(string_aa).replace("'","")
typesofpts_featured_list_new.append(string_bb+"_HT")
typesofpts_featured_list_new.append(string_bb+"_AT")
scoreline_changes = page_soup.findAll("td", {"class": "styles__EventData-sc-18qpy7g-1 eyWugu"})
matchscorelinelist = []
for i in scoreline_changes:
string_aaa = str(i)
string_bbb = string_aaa.replace(" ","")
extracter_aaa = (re.findall(r'(?<=>)[^<:]+(?=:?<)',string_bbb)[0:500])
extract_bbb = extracter_aaa[1::3]
matchscorelinelist.append(extract_bbb)
df_scoreevents_a = pd.DataFrame(matchscorelinelist)
df_scoreevents = df_scoreevents_a.T
df_scoreevents.columns = typesofpts_featured_list_new
df_scoreevents_counts_a = pd.DataFrame(df_scoreevents.count(axis='rows'))
df_scoreevents_counts = df_scoreevents_counts_a.T
dataframes = [maindata_df, df_scoreevents_counts]
df_combined = pd.concat(dataframes, axis=1)
allmatchcodes_list.append(df_combined)
all_matches_df = pd.concat(allmatchcodes_list).fillna(0)
all_matches_df['Final_Scoreline_Margin'] = abs(all_matches_df['HomeTeamScore'] - all_matches_df['AwayTeamScore'])
all_matches_df.to_csv(r'C:\Desktop\all_matches_df.csv', index = False, header=True)

